

Dzisiaj zajmujemy się prognozowaniem wyjściowej mocy elektrowni przy użyciu modelu regresji liniowej.
Źródło danych: https://archive.ics.uci.edu/ml/datasets/Combined+Cycle+Power+Plant
Forma artykułu
W tej i w następnej części tej publikacji przedstawiony został proces tworzenia modeli prostej regresji liniowej. Autor artykułu zrezygnował z przedstawiania tego procesu w formie wzorów matematycznych ponieważ uznał, że bardziej praktycznie będzie pokazanie użycie nowoczesnych bibliotek języka Python. Wszystkie wykorzystane tu narzędzia ją bezpłatne i powszechnie dostępne w Internecie. W tej publikacji wykorzystana została głównie biblioteka statsmodels zbudowaną na bazie pakietów NumPy i SciPy języka Python. Wszystkie operacje zostały przeprowadzone w notatniku Jupyter należącym do bezpłatnego pakietu Anaconda. Czytelnik wprowadzając podany w publikacji kod uzyska te same wyniki, co może stanowić zachętę do głębszego zainteresowania zaprezentowanymi tutaj narzędziami.
Przegląd danych
Zbiór danych zawiera 9568 pomiarów z 6 lat (2006-2011), zebranych w elektrowni o cyklu łączonym. Podczas pomiaru elektrownia była wykorzystywana do pracy z pełnym obciążeniem.
Przedmiotem pomiaru były następujące zmienne:
- średnie godziny zmienne temperatury temperatury (T),
- zawartości satelitarne (R)
- wilgotność względna (RH)
- próżnia spalin (V).
Te zmienne niezależne umożliwiały przegląd godzinowej wydajności energii elektrycznej netto (EP).
Elektrownia o cyklu kombinowanym (CCPP) składa się z turbin gazowych (GT), turbin parowych (ST) i generatorów pary z odzyskiem ciepła. W elektrowni typu CCPP energia elektryczna jest wytwarzana przez turbiny gazowe i parowe, które są powiązane w jednym cyklu i gdzie nośniki energii są przenoszone z jednej turbiny do drugiej. Podczas gdy mierzona próżnia ma wpływ na turbinę parową, pozostałe trzy zmienne oddziaływania wpływają na wydajność turbin gazowych GT.
Prognozowanie przy użyciu modelu regresji liniowej
Otwieramy źródło danych i potrzebne biblioteki języka Python. Obliczenia zostały przeprowadzone w notatniku Jupyter.
import pandas as pd
import numpy as np
import itertools
from itertools import chain, combinations
import statsmodels.formula.api as smf
import scipy.stats as scipystats
import statsmodels.api as sm
import statsmodels.stats.stattools as stools
import statsmodels.stats as stats
from statsmodels.graphics.regressionplots import *
import matplotlib.pyplot as plt
import seaborn as sns
import copy
#from sklearn.cross_validation import train_test_split
import math
## https://archive.ics.uci.edu/ml/datasets/Combined+Cycle+Power+Plant
df = pd.read_excel('c:/1/Folds5x2_pp.xlsx')
df.sample(5)
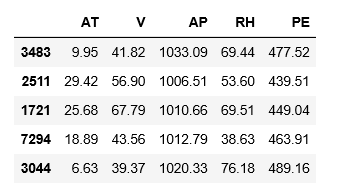
Zbiór pomiarów ma postać tabeli, gdzie kolumny reprezentują zmienne niezależne. Ostatnia kolumna oznaczona jako PE reprezentuje zmienną zależną (wynikową).
Poniżej została przeprowadzona analiza wielkość zbioru i formatu danych.
df.shape
Dane składają się z 9 568 wierszy w pięciu kolumnach.
(9568, 5)
df.dtypes
Dane mają postać liczbową.

Dla lepszej czytelności zmieniamy oznaczenia kolumn.
df.columns
![]()
df.columns = ['Temperature', 'Exhaust_Vacuum', 'Ambient_Pressure', 'Relative_Humidity', 'Energy_output'] df.sample(5)
Nazwy kolumn zostały zmienione.

Warunki podstawowe przy zastosowaniu modelu regresji liniowej
Niedotrzymanie podstawowych warunkami regresji może prowadzić do stworzenia modelu nie odzwierciedlającego prawdziwych relacji pomiędzy zmiennymi niezależnymi i zmienną zależną.
- Między predyktorami i zmienną wynikową musi być zachowana relacja liniowa.
- Nie może istnieć silna korelacja pomiędzy zmiennymi niezależnymi.
- Wartości resztkowe powinny mieć rozkład normalność. Indywidualne reszty modelu powinny być podobne w swej zbiorowości oraz mieć rozkład normalny.
- Homogeniczność wariancji - wariancja błędu powinna być stała.
- Niezależność - błędy związane z jedną obserwacją nie mogą być skorelowane z błędami innych obserwacji.
Analiza danych liniowych między zmienną zależną a zmiennymi niezależnymi
CORREL = df.corr().sort_values('Energy_output')
CORREL['Energy_output']
Test korelacji ujawnił bardzo dużą korelację ujemną Temperatury i Próżni spalin z wartością produkowanego prądu.

Zestawienie zawiera minimalne i maksymalne wahania wartości zmiennych egzogenicznych:
- Temperatura (T) w zakresie od 1,81 ° C do 37,11 ° C,
- Obejmuje powierzchnię (AP) w zakresie od 992,89 do 1033,30 milibara,
- Wilgotność względna (RH) w zakresie od 25,56% do 100,16%
- Próżnia spalin (V) w zakresie od 25,36 do 81,56 cm Hg
Dane są pobierane z czujników rozmieszczonych w zakładzie, które co sekundę rejestrują zmienne otoczenia. Zmienne nie zostały objęte normalizacji (standaryzacją danych).
- Zmienna zależna (wynikowa) to godzinowa produkcja energii elektrycznej netto (EP) zarejestrowana w zakresie od 420.26 do 495,76 MW
Jak wspomnieliśmy istnieje bardzo wysoka korelacja ujemna między zmienną wynikową produkcją energii elektrycznej (EP) a temperatura i próżnia spalin.
Jednoczynnikowy model regresji liniowej
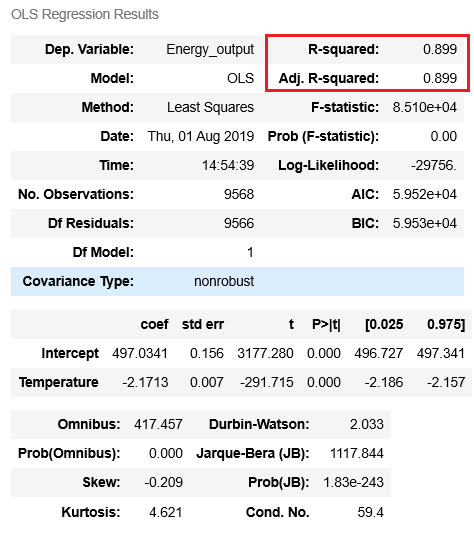
lm = smf.ols(formula = 'Energy_output ~ Temperature', data = df).fit() lm.summary()
Jednoczynnikowy model regresji w oparciu o zakresy dostępne są najlepsze właściwości prognostyczne.
plt.figure()
plt.scatter(df.Temperature, df.Energy_output, c = 'grey')
plt.plot(df.Temperature, lm.params[0] + lm.params[1] * df.Temperature, c = 'r')
plt.xlabel('Temperature')
plt.ylabel('Energy_output')
plt.title("Linear Regression Plot")
Parametr r2 ujawnia niezwykle dobre właściwości predykcyjne modelu. Poniższy wykres obrazuje jak dobry jest wykonany przez nas model.

Wieloczynnikowy model regresji liniowej
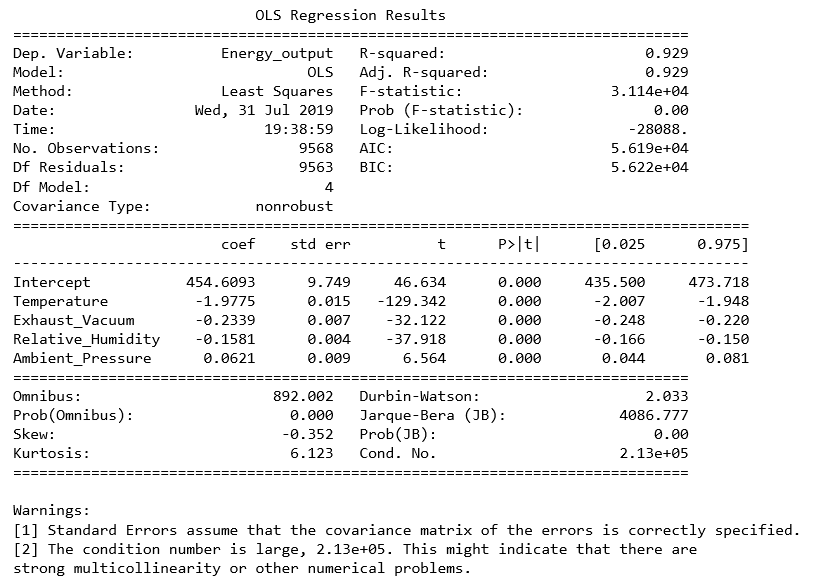
lm = smf.ols(formula = 'Energy_output ~ Temperature + Exhaust_Vacuum + Relative_Humidity + Ambient_Pressure', data = df).fit() print (lm.summary())
Model wieloczynnikowej regresji liniowej cechuje się doskonałymi zdolnościami predykcyjnymi. Dlatego jego wyniki wzbudzają niepokój.
df.describe()

plt.rcParams['figure.figsize'] = (5, 4) sns.distplot(df['Energy_output'])
Wykres rozkładu prawdopodobieństwa wykazał istnienie dwóch ekstremów (wykres bimodalny).

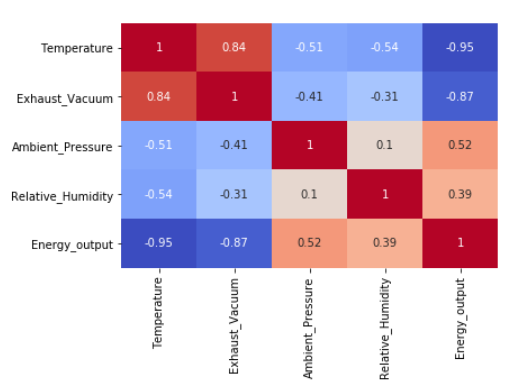
plt.rcParams['figure.figsize'] = (5, 4) sns.heatmap (df.corr (), cmap="YlGnBu")
Jak pamiętamy jednym z warunków prawidłowego modelu regresji liniowej jest brak korelacji pomiędzy zmiennymi egzogenicznymi.

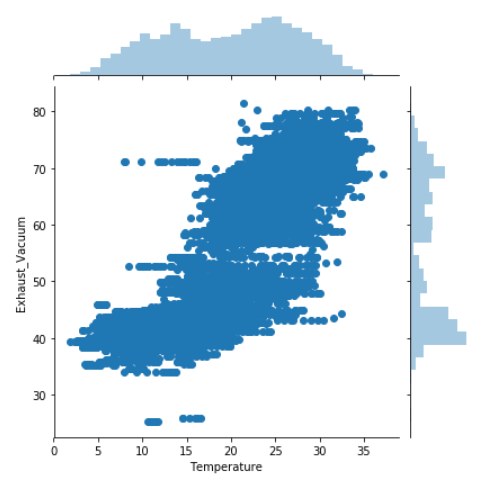
Widać wyraźnie że między zmiennymi opisującymi ‘Temperature" oraz "Exhaust_Vacuum" występują bardzo wysokie korelacje dodatnie.
Poniżej przedstawiłem inną formę prezentacji tej samej macierzy korelacji.
sns.heatmap (df.corr (), cmap="coolwarm", annot=True, cbar=False)
df.isnull().sum()

Graficzna analiza wpływu zmiennych niezależnych na zmienną wynikową
Aby zobaczyć jaki jest wpływ wszystkich zmiennych niezależnych na zmienną zależną dzielę zbiór zmiennych wynikowych na dwie części. Do tabeli danych zostaje dodana kolumna zawierająca dwa stany produkcji energii.
Ewa = ['małą moc', 'duża moc'] df['moc'] = pd.qcut(df['Energy_output'],2, labels=Ewa) df.sample(2)
Tworzymy wykres zależności.
sns.pairplot(data=df[['Temperature' ,'Exhaust_Vacuum','Ambient_Pressure', 'Relative_Humidity', 'moc']], hue='moc', dropna=True, height=2)

Wykres zależności kolejny raz wykazał wysoką korelację wzorów między Temperaturą (T) i Próżnią spalin (V) .
sns.jointplot(x='Temperature', y='Exhaust_Vacuum', data=df)
W drugiej części tego artykułu przeprowadzony zostanie proces weryfikacji warunków podstawowych tworzenia liniowej regresji wielorakiej.