

EN240120201439
The kernel method involves bending two-dimensional space. this is perfectly explained here: https://shapeofdata.wordpress.com/2013/05/27/kernels/
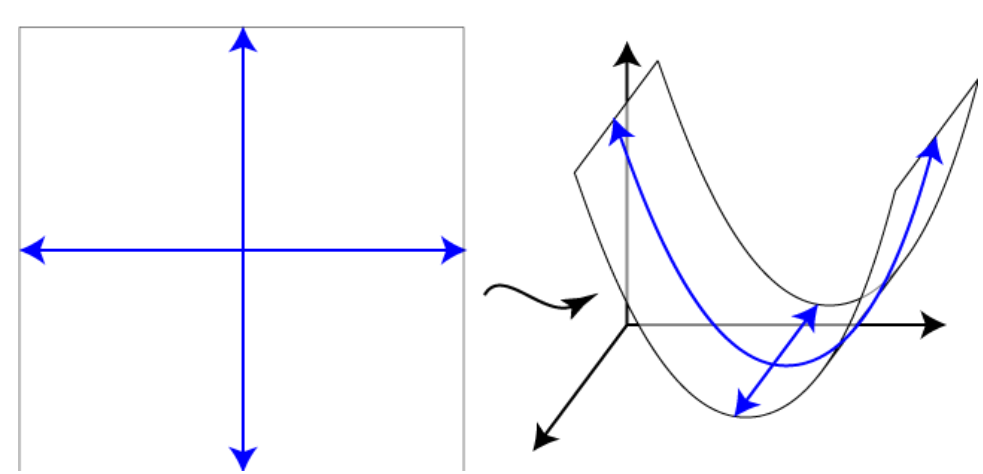
Two-dimensional data live in a two-dimensional plane, which we can consider as a piece of paper. The nucleus is a way to place this two-dimensional plane in a space with higher dimensions. In other words, the nucleus is a function from a low-dimensional space to a higher-dimensional space.
So, for example, we can place a plane in three-dimensional space so that it curves along one axis, as in the figure below. Here, the cross-sections of the plane in three-dimensional space are parabolas.
The purpose of the kernel is to make two classes of data points, which can only be separated by a curved line in two-dimensional space, can be separated by a flat plane in three-dimensional space.
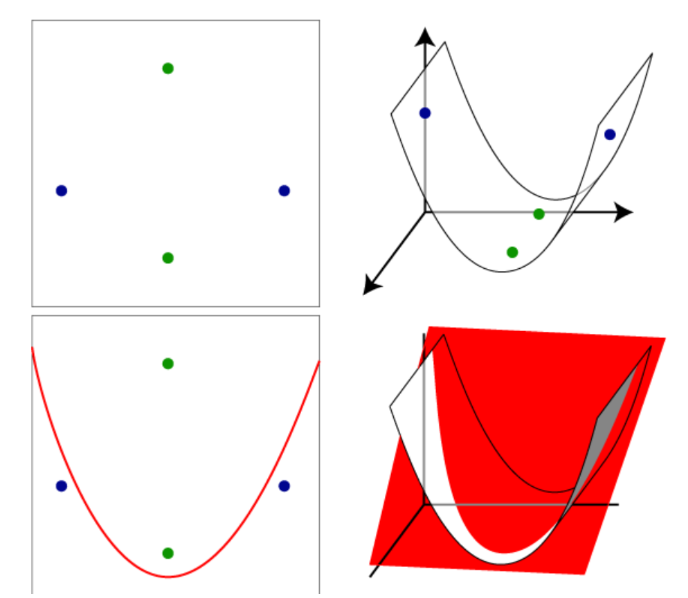
By adding more dimensions, we increase the flexibility of lines / planes / hyperplanes to move. For example, in the data set shown below on the left there is clearly no line separating the two blue points from the two green points. However, when we place this data set in three dimensions using the nucleus of the first figure, the two blue points will be raised, as on the right, so there is now another plane (drawn in red) that separates the blue from the green, shown in the lower right corner . This plane intersects the two-dimensional space on the curve shown in the lower left drawing.
In general, the kernel does it so that each plane in three-dimensional space intersects a two-dimensional plane that contains our data in a curve line, not a straight line. If we use a nucleus that places the plane in an even higher dimensional space, then the hyperplanes in these higher spaces intersect the two-dimensional space on potentially more complex curves, which gives us more flexibility in choosing the curve separating the data.
It is worth choosing the simplest possible kernel, is that, as in the case of general regression, the greater the flexibility of the model, the greater the risk of over-fitting.
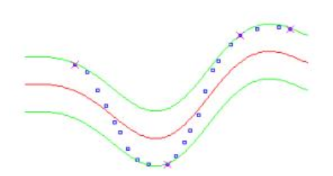
The epsilon borders are given in green lines. Blue points represent data instances.
The larger the epsilon parameter, the more skewed the model will be flattened
SVM generalization performance (estimation accuracy) depends on the setting of good meta-parameters C, and kernel parameters.
Parameter C
Parameter C specifies the compromise between the complexity of the model (flatness) and the degree to which deviations greater than are tolerated in the optimization formula, for example, if C is too large (infinity), then the goal is to minimize only the empirical risk, without taking into account part of the model’s complexity optimization formulation.
The parameter controls the width of the sensitivity zone used for training data. The value can affect the number of helper vectors used to construct the regression function. The larger, the less selected auxiliary vectors. On the other hand, higher values result in more “flat” estimates.
RBF kernel
In machine learning, the radial basis function kernel, or RBF kernel, is a popular kernel function used in various kernelized learning algorithms. In particular, it is commonly used in support vector machine classification.
import numpy as np
from sklearn.svm import SVR
import matplotlib.pyplot as plt
Example 1 non-linear kernels SVM SVR(kernel=’rbf’)
x = np.sort(6 * np.random.rand(20, 1), axis=0)
y = np.sin(x).ravel()
plt.figure()
plt.plot(x, y, 'ko', color ='blue', label="Original Noised Data")
plt.legend()
plt.axhline(y=0, color='black', linestyle='--', lw=0.5)
plt.axvline(x= 0, color = 'black', linestyle='--', lw=0.5)
plt.show()

Dokonujemy zniekształcenia wykresu sinusoidalnego.
y = (0.3 * (0.05-np.random.rand(20)))+y #<<<< distorting element
plt.figure()
plt.plot(x, y, 'ko', color ='blue', label="Original Noised Data")
plt.legend()
plt.axhline(y=0, color='black', linestyle='--', lw=0.5)
plt.axvline(x= 0, color = 'black', linestyle='--', lw=0.5)
plt.show()

print(x.shape)
print(y.shape)
Model SVM non-linear kernels
SVR(kernel=’rbf’)
svr_rbf = SVR(kernel='rbf', C=100, gamma=0.1, epsilon=.1)
# Fit the SVM model according to the given training data.
y_pred = svr_rbf.fit(x, y).predict(x)
import pandas as pd
RBF = pd.DataFrame({'y_actual': y, 'y_predicted': y_pred})
RBF.head(5)
Get parameters for this estimator.
from sklearn import metrics
RBF.head(50).plot()

plt.plot(x, y, 'o', color ='blue', label ="data")
plt.plot(x, y_pred, '--', color ='red', label ="Fitted Curve")
plt.legend()
plt.show()
a = svr_rbf.score(x , y , sample_weight = None)
print('Mean Squared Error:

model summary
a = svr_rbf.score(x , y , sample_weight = None)
print('Return the coefficient of determination R^2 of the prediction.')
print('Mean Squared Error:
print('Get parameters for this estimator.')
svr_rbf.get_params(deep=True)
y_pred=svr_rbf.predict(x)
Example 2 non-linear kernels SVM SVR(kernel=’rbf’)
x = np.linspace(0, 10, num = 40)
y = 17.45 * np.sin(0.2 * x) + np.random.normal(size = 40)
y = (0.01 * (0.5-np.random.rand(40)))+y #<<<< distorting element
plt.figure()
plt.figure(figsize=(17,4))
plt.plot(x, y, 'ko', color ='blue', label="Original Noised Data")
plt.legend()
plt.show()
x.shape

Adds a dimension to the x vector.
df = pd.DataFrame(x)
x = np.asarray(df)
x.shape
Model SVM non-linear kernels
SVR(kernel=’rbf’)
svr_rbf = SVR(kernel='rbf', C=100, gamma=0.1, epsilon=.1)
# Fit the SVM model according to the given training data.
y_pred = svr_rbf.fit(x, y).predict(x)
import pandas as pd
RBF = pd.DataFrame({'y_actual': y, 'y_predicted': y_pred})
RBF.head(5)
plt.figure(figsize=(17,4))
plt.plot(x, y, 'o', color ='blue', label ="data")
plt.plot(x, y_pred, '--', color ='red', label ="Fitted Curve")
plt.legend()
plt.show()
a = svr_rbf.score(x , y , sample_weight = None)
print('Mean Squared Error:

model summary
y_pred=svr_rbf.predict(x)
a = svr_rbf.score(x , y , sample_weight = None)
print('Return the coefficient of determination R^2 of the prediction.')
print('Mean Squared Error: print('Get parameters for this estimator.')
svr_rbf.get_params(deep=True)
Example 3 non-linear kernels SVM SVR(kernel=’rbf’)
x = np.linspace(-10, 10, num = 300)
y = 1.75 * np.cosh(0.168 * x) + np.random.normal(size = 300)
y = (1.21 * (2.5-np.random.rand(300)))+y #<<<< distorting element
plt.figure()
plt.figure(figsize=(17,4))
plt.plot(x, y, 'ko', color ='blue', label="Original Noised Data")
plt.legend()
plt.show()

Adds a dimension to the x vector.
print(x.shape)
df = pd.DataFrame(x)
x = np.asarray(df)
print(x.shape)
Model SVM non-linear kernels
SVR(kernel=’rbf’)
svr_rbf = SVR(kernel='rbf', C=100, gamma=0.1, epsilon=0.1)
# Fit the SVM model according to the given training data.
y_pred = svr_rbf.fit(x, y).predict(x)
import pandas as pd
RBF = pd.DataFrame({'y_actual': y, 'y_predicted': y_pred})
RBF.head(5)
plt.figure(figsize=(17,4))
plt.plot(x, y, 'o', color ='blue', label ="data")
plt.plot(x, y_pred, '--', color ='red', linewidth=5, label ="Fitted Curve")
plt.text(-6, 7.5, r'C=100, gamma=0.1, epsilon=0.1', fontsize=28)
plt.legend()
plt.show()
a = svr_rbf.score(x , y , sample_weight = None)
print('Mean Squared Error:

y_pred=svr_rbf.predict(x)
a = svr_rbf.score(x , y , sample_weight = None)
print('Return the coefficient of determination R^2 of the prediction.')
print('Mean Squared Error: print('Get parameters for this estimator.')
svr_rbf.get_params(deep=True)
svr_rbf = SVR(kernel='rbf', C=100, gamma=6.1, epsilon=.1)
# Fit the SVM model according to the given training data
y_pred = svr_rbf.fit(x, y).predict(x)
plt.figure(figsize=(17,4))
plt.plot(x, y, 'o', color ='blue', label ="data")
plt.plot(x, y_pred, '--', color ='red', linewidth=5, label ="Fitted Curve")
plt.text(-6, 7.5, r'C=100, gamma=6.1, epsilon=0.1', fontsize=28)
plt.legend()
plt.show()
a = svr_rbf.score(x , y , sample_weight = None)
print('Mean Squared Error:

svr_rbf = SVR(kernel='rbf', C=100, gamma=0.1, epsilon=3.4)
# Fit the SVM model according to the given training data
y_pred = svr_rbf.fit(x, y).predict(x)
plt.figure(figsize=(17,4))
plt.plot(x, y, 'o', color ='blue', label ="data")
plt.plot(x, y_pred, '--', color ='red', linewidth=5,label ="Fitted Curve")
plt.text(-6, 7.5, r'C=100, gamma=0.1, epsilon=3.4', fontsize=28)
plt.legend()
plt.show()
a = svr_rbf.score(x , y , sample_weight = None)
print('Mean Squared Error:

svr_rbf = SVR(kernel='rbf', C=6100, gamma=0.1, epsilon=0.1)
# Fit the SVM model according to the given training data
y_pred = svr_rbf.fit(x, y).predict(x)
plt.figure(figsize=(17,4))
plt.plot(x, y, 'o', color ='blue', label ="data")
plt.plot(x, y_pred, '--', color ='red', linewidth=5, label ="Fitted Curve")
plt.text(-6, 7.5, r'C=6100, gamma=0.1, epsilon=0.1', fontsize=28)
plt.legend()
plt.show()
a = svr_rbf.score(x , y , sample_weight = None)
print('Mean Squared Error:

Użycie innego rodzaju jądra
svr_lin = SVR(kernel='linear', C=100, gamma='auto')
svr_poly = SVR(kernel='poly', C=100, gamma='auto', degree=3, epsilon=.1,
coef0=1)
x = np.linspace(-10, 10, num = 260)
y = 1.75 * np.exp(0.17 * x) + np.random.normal(size = 260)
plt.figure()
plt.figure(figsize=(17,4))
plt.plot(x, y, 'ko', color ='blue', label="Original Noised Data")
plt.legend()
plt.axhline(y=0, color='black', linestyle='--', lw=0.5)
plt.axvline(x= 0, color = 'black', linestyle='--', lw=0.5)
plt.show()

print(x.shape)
df = pd.DataFrame(x)
x = np.asarray(df)
print(x.shape)
svr_rbf = SVR(kernel='rbf', C=100, gamma=0.1, epsilon=3.4)
svr_linear = SVR(kernel='linear', C=100, gamma='auto')
svr_poly = SVR(kernel='poly', C=100, gamma='auto', degree=3, epsilon=.1,
coef0=1)
# Fit the SVM model according to the given training data
y_pred_rbf = svr_rbf.fit(x, y).predict(x)
y_pred_linear= svr_linear.fit(x, y).predict(x)
y_pred_poly = svr_poly.fit(x, y).predict(x)
plt.figure(figsize=(17,8))
plt.plot(x, y, 'o', color ='lightgrey', label ="data")
plt.plot(x, y_pred_rbf, '--', color ='red', linewidth=2,label ="Fitted Curve: rbf")
plt.plot(x, y_pred_linear, color ='black', linewidth=2,label ="Fitted Curve: linear")
plt.plot(x, y_pred_poly, '--', color ='blue', linewidth=2,label ="Fitted Curve: poly")
#plt.text(-6, 7.5, r'C=100, gamma=0.1, epsilon=3.4', fontsize=28)
plt.legend()
plt.show()
rbf = svr_rbf.score(x , y , sample_weight = None)
print('Mean Squared Error rbf: linear = svr_linear.score(x , y , sample_weight = None)
print('Mean Squared Error svr_linear: poly = svr_poly.score(x , y , sample_weight = None)
print('Mean Squared Error svr_poly:
