

This time we use model which is designed to classification application.

The SVM Support Vector Machine algorithm is included among the learning machine estimators based on the classification and regression analysis processes.
The SVM classifier uses an optimization algorithm based on maximizing the margin of the hyperplan. The SVM algorithm is designed to conduct the best possible classification of results. Vectors separating hyperspace can be linear or (thanks to the SVC function) non-linear.
In our model, we will use the linear SVM Support Vector Machine classifier.
We download all needed libraries and database file.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pprint
from sklearn.pipeline import Pipeline
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.externals import joblib
df = pd.read_csv('c:/2/poliaxid.csv', index_col=0)
del df['nr.']
df.head(3)

Next we point the column y with the result of the calculations, and columns with independent variables X.
X=df.drop(['quality class'],axis=1) Y=df['quality class']
Pipeline put together standardization and classification.
ew = [('scaler', StandardScaler()), ('SVM', SVC())]
pipeline = Pipeline(ew)
parameteres = {'SVM__C':[0.001,0.1,10,100,10e5], 'SVM__gamma':[0.1,0.01]}
X_train, X_test, y_train, y_test = train_test_split(X,Y,test_size=0.2, random_state=30, stratify=Y)
grid = GridSearchCV(pipeline, param_grid=parameteres, cv=5)
grid.fit(X_train, y_train)
print("score =
I can see which superparamiters was chosen by the grid as the best.
pparam=pprint.PrettyPrinter(indent=2) print(grid.best_params_)
![]()
y_pred = grid.predict(X_test)
Classificator is evaluation by confusion matrix.
from sklearn.metrics import classification_report, confusion_matrix print(confusion_matrix(y_test, y_pred)) print(classification_report(y_test, y_pred))
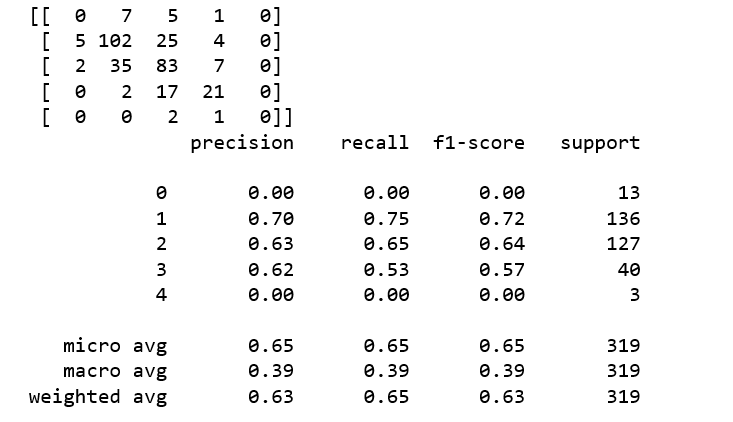
The SVM Support Vector Machine is not better clasificator than not adapted to such a role Random Forest regression.