

Krzywa jakości dyskryminacji ROC
Krzywa ROC została po raz pierwszy zastosowana podczas II wojny światowej do analizy sygnałów radarowych, zanim została zastosowana w teorii wykrywania sygnałów . [40] Po ataku na Pearl Harbor w 1941 r. Armia Stanów Zjednoczonych rozpoczęła nowe badania w celu zwiększenia prognoz poprawnie wykrytych japońskich samolotów na podstawie sygnałów radarowych. W tym celu zmierzyli zdolność operatora odbiornika radarowego do dokonania tych ważnych rozróżnień, które nazwano Charakterystyką Operacyjną Odbiornika. [41]
W latach 50. XX wieku w psychofizyce stosowano krzywe ROC do oceny wykrywania słabych sygnałów u ludzi (a czasem także u zwierząt innych niż ludzie). [40] W medycynie analiza ROC była szeroko stosowana w ocenie testów diagnostycznych . [42] [43] Krzywe ROC są również szeroko stosowane w epidemiologii i badaniach medycznych i są często wymieniane w połączeniu z medycyną opartą na dowodach .
Źródło: https://en.wikipedia.org/wiki/Receiver_operating_characteristic#History
Ustawienie progów w modelu regresji logistycznej
Ustawienie progów w modelu regresji logistycznej jest jednym z najważniejszych czynności podczas procesu klasyfikacji. Klasyfikacja binarna polega na wyodrębnieniu z pośród danych dwóch lub więcej klas. Załóżmy, że chodzi klasyfikację dychotomiczną, zero-jedynkową. Próg to granice jaką stawia model między obiema klasami. Progi jak również Confuse Matrix czy parametry ROC i AUC dotyczą modeli klasyfikacji, nie muszą dotyczyć wyłącznie modelu regresji logistycznej.
Co to jest próg w modelu regresji logistycznej?
Załóżmy, że mamy model klasyfikujący strony internetowe na przydatne i nieprzydatne.
Model regresji logistycznej rozróżnia strony wg jedne zmiennej ciągłej.
Strony przydatne zaznaczone są na zielono, strony nieprzydatne zaznaczone są na czerwono.
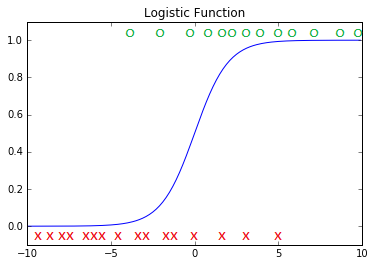
Model regresji logistycznej jest symbolizowany przez niebieską krzywą.
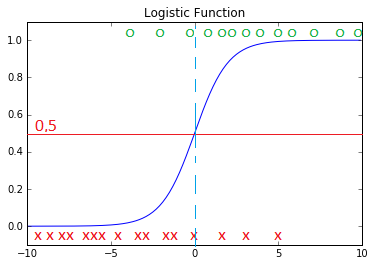
W modelu przyjęto domyślny próg 0,5 dokonujący klasyfikacji (dzielący) strony na przydatne i nieprzydatne.
Czerwona linia przedstawia próg 0,5. Jest to wysokość prawdopodobieństwa, że strona internetowa jest przydatna albo nieprzydatna dla użytkownika.
Błękitna pionowa linia dzieli strony na przydatne i nieprzydatne.
Teraz pokażemy to na Confuse Matrix.
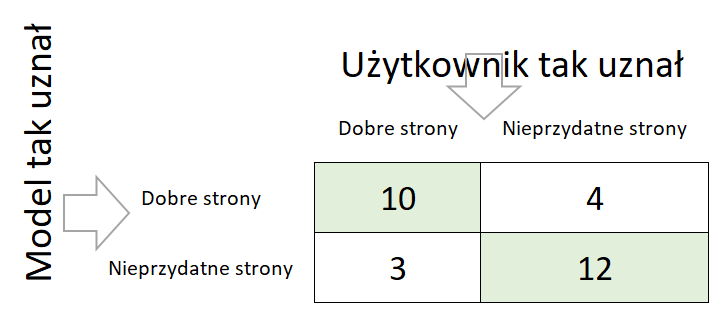
Recall 0,77
10/(10+3), 13 stron uważanych przez użytkownika za dobre model wytypował 10.
Precision 0,71
10/(10+4), 10 stron z 14 wytypowanych przez model było dobrych dla użytkownika.
Teraz zmienimy ustawienie progów w modelu regresji logistycznej
Tym razem zmieniliśmy próg prawdopodobieństwa do poziomu 0,2.
Model sklasyfikował więcej stron jako strony przydatne, niestety odbyło się to kosztem precyzji.


Recall 0,85
11/(11+2), 13 stron uważanych przez użytkownika za dobre model wytypował 11.
Precision 0,69
11/(11+5), 11 stron z 16 wytypowanych przez model było dobrych dla użytkownika.
Teraz zwiększymy ustawienie progu do 90% prawdopodobieństwa
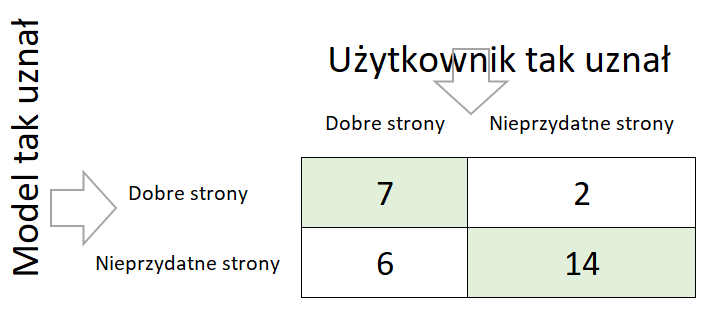
Recall 0,54
7/(7+6), 13 stron uważanych przez użytkownika za dobre model wytypował 7.
Precision 0,78
7/(7+2), 7 stron z 9 wytypowanych przez model było dobrych dla użytkownika.
Jak ustawić próg w modelu regresji logistycznej
Próg ustawiamy w zależności od tego co jest ważniejsze. Czy odrzucenie wartościowych stron jest miej kosztowne od zakwalifikowania dobrych stron jako bezwartościowych? Czy gorsza jest klasyfikacja złej strony jako dobrej, czy na odwrót.
Próg prawdopodobieństwa można ustawić na dowolną wartość z przedziału od 0 do 1. Jak więc określić, który próg jest najlepszy? Czy jest jakiś inny sposób aby nie szukać ręcznie idealnych proporcji recall/precision? Każda konfiguracja progu prawdopodobieństwa daje inną confusion matrix, którą trzeba ocenić.
Krzywa ROC
Tak wygląda krzywa ROC (Receiver Operating Characteristics). Kiedyś przyjmowano , że czym większe jest pole pod krzywą AUC (Area Under The Curve) tym lepszy jest operator radaru, czyli przekładając na język współczesny, tym lepszy proces klasyfikacji modelu.

źródło: https://towardsdatascience.com/understanding-auc-roc-curve-68b2303cc9c5
Doskonały klasyfikator
Gdy mamy do czynienia z doskonałą klasyfikacją, wtedy confuse matrix pokaże taki wynik.
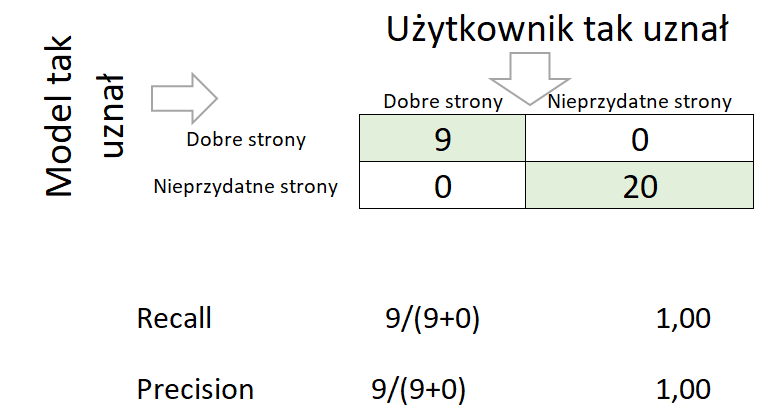
Confusion Matrix

source: https://towardsdatascience.com/beyond-accuracy-precision-and-recall-3da06bea9f6c
Najważniejsze wskaźniki dla confusion matrix to Precision i Recall.
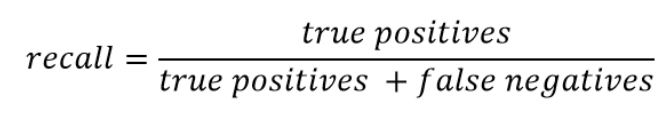
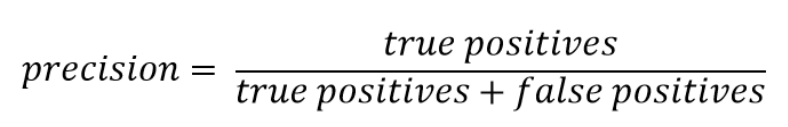
Recall wyraża zdolność do znalezienia wszystkich odpowiednich instancji w zbiorze tych instancji (np. na 10 jabłek znalazł 9 jabłek, 9/10=0.90 ).
Precision wyraża odsetek punktów danych, które według naszego modelu były istotne, ze wszystkich znalezionych danych (np. komputer znalazł 20 owoców z czego 9 jabłek, szukaliśmy jabłek więc: 9/20 = 0.45)
Załóżmy, że budujemy model wykrywaniem narkotyków na bramkach lotniska. Narkotyki przemyca może 0.01% wszystkich pasażerów. Jeżeli model nie będzie w stanie wykryć nikogo na bramkach, wtedy recall =0, precision wyniesie również 0. Jeżeli model uzna wszystkich za przemytników recall bezie 100%, precision 2%, ale bardzo wielu niewinnych ludzi nie poleci samolotem.
Jak pogodzić recall z precision?
Przykład narkotyków jest trudny ponieważ chcemy znaleźć wszystkich przemytników, jednak nie chcemy tego robić kosztem innych pasażerów. Przyjmuje się, że wskaźnikiem optymalizującym recall z precision jest średnia harmoniczna F1.

Czym wyższa wartość F1 tym lepiej. Ponieważ w liczniku jest iloczyn, jeżeli któryś ze składników przyjmuje bardzo niskie wartości (np. bliskie zeru), wskaźnik F1 również przyjmie niskie wartości. Wskaźnik F1 jest więc czuły na wartości skrajne oby wskaźników.
Stosunek pomiędzy recall i precision można zobrazować czerwoną linią na poniższym wykresie.
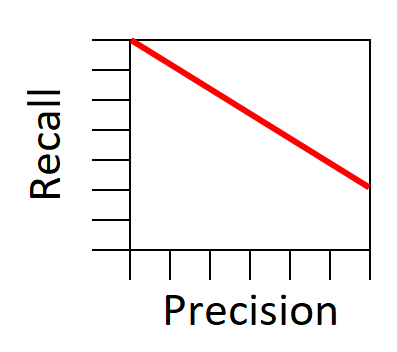
Spróbujmy odwrócić nieco ten wykres.
Recall znaczy True positive rate, czyli udział dobrze wybranych instancji w zbiorze tych instancji. W naszym przykładzie były to jabłka. Obszar recall zaznaczony jest kolorem zielonym.

Teraz spróbujmy wyobrazić sobie identyczny wskaźnik tylko dla pomarańczy. Procentowy udział znalezionych pomarańczy w zbiorze wszystkich pomarańczy.
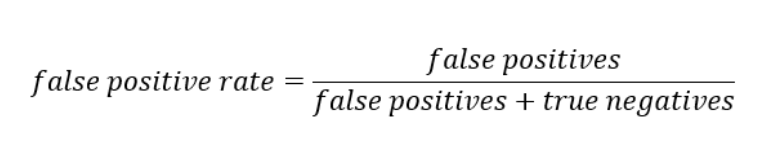
Wskaźnik ten można opisać na confuse matrix kolorem pomarańczowym.

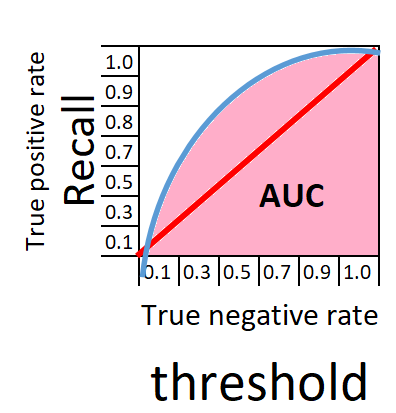
Teraz spróbujmy narysować na schematycznym wykresie zależność pomiędzy True Positive Rate i False Positive Rate.
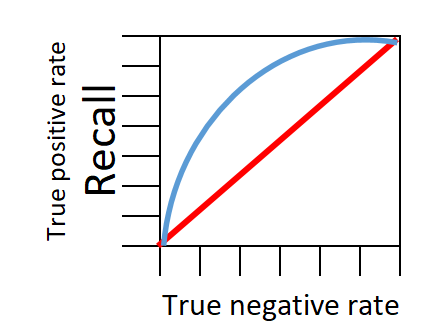
Czerwona linia na wykresie wskazuje klasyfikator losowy (tzw. naive classifier) , czyli najgorszy z możliwych. Niebieska linia pokazuje klasyfikator inteligentny, nie losowy. Im bliżej niebieska linia zbliży się do lewego górnego rogu wykresu tym klasyfikator jest lepszy.
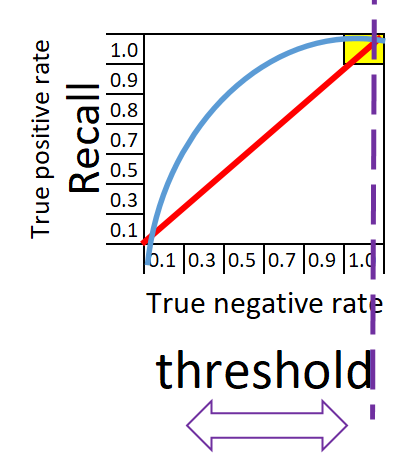
Możemy rozpatrzeć kilka skrajnych sytuacji. Gdy próg przesuniemy do końca prawej strony wykresu, mamy recall =1.0 i True negative rate = 1. Bezbłędnie wybraliśmy wszystkie jabłka i wszystkie pomarańcze jakie były w koszyku.
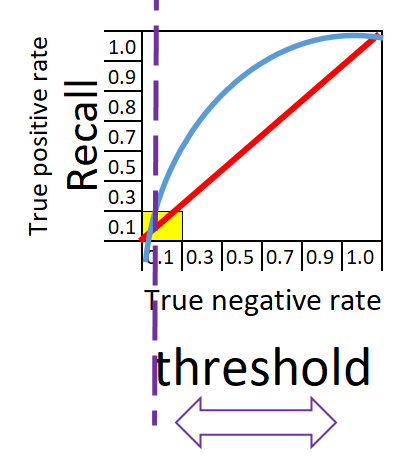
W lewym dolnym rogu wykresu nie zostały znalezione żadne owoce.
Recall = 0, True negative rate = 0
W zależności od potrzeb można przesuwać próg (threshold) w kierunku lewym aby model klasyfikował ze skłonnością na recall lub przeciwnie na True negative rate. Idealnie klasyfikujący model będzie miał wykres pozbawiony krzywej. Klasyfikator taki na poniższym wykresie przyjmie postać niebieskiej linii. Klasyfikator 100% dla jabłek i dla pomarańczy, zbiera wszystkie. Przeciwieństwem idealnego klasyfikatora jest klasyfikator losowy przedstawiony za pomocą czerwonej linii. W praktyce spotykamy się z klasyfikatorami które znajdują się w przestrzeni pomiędzy czerwoną a niebieską linią.

Jakość klasyfikatora odzwierciedlona jest polem powierzchni AUC pod krzywą klasyfikacji ROC.
Na poniższym wykresie powierzchnia AUC (Area under the curve) została przedstawiona kolorem różowym.
Differentiation between Recall and Precision explained in plain English