Jak wykazałem w poprzednich wpisach informacja o normalności rozkładu danych jest bardzo ważna. W metodologii Six Sigma rozkład normalny danych ma ogromne znaczenie, ponieważ pozwala na zastosowanie wielu praktycznych narzędzi oraz zasad przydatnych przy interpretowaniu zjawisk. Należy pamiętać, że rozkład normalny stosowany jest przede wszystkim dla danych ciągłych.
Jeżeli zbiór zawiera dużo elementów, do określenia normalności rozkładu można wykorzystać histogram
Histogram jest wykresem, który grupuje dane i pokazuje jak wiele pomiarów znajduje się w kolejnych przedziałach.
Specjalną formą histogramu jest wykres kropkowy (Dotplot).
Poniżej przedstawiony jest wykres punktowy czasu obsługi klienta w urzędzie. Każda kropka reprezentuje trzech klientów. Miejsce kropki określa w jakim czasie klienci zostali obsłużeni w urzędzie. Najwięcej klientów zostało obsłużonych w urzędzie w czasie od 10 do 20 minut.

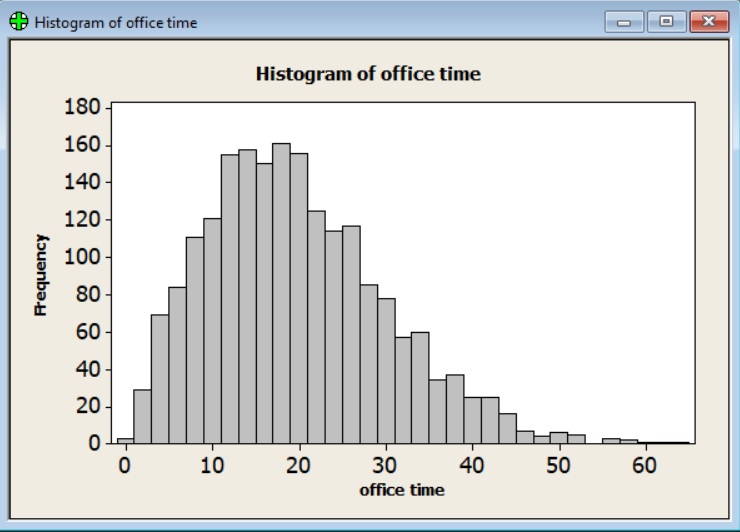
Poniżej przedstawiony jest histogram na podstawie tych samych danych, które były użyte do wykresu punktowego. Wysokość każdego słupka reprezentuje ilość klientów, którzy zostali obsłużeni w określonym na osi x przedziale czasu.
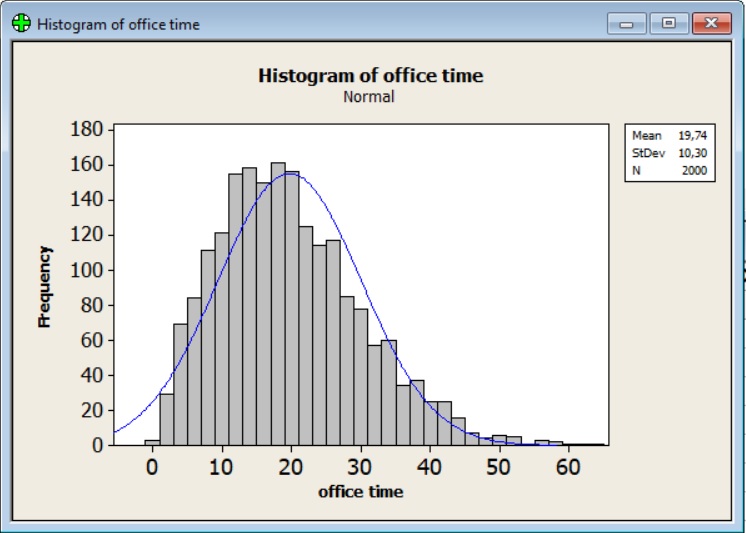
Minitab daje możliwość porównania histogramu do rozkładu normalnego gęstości prawdopodobieństwa.
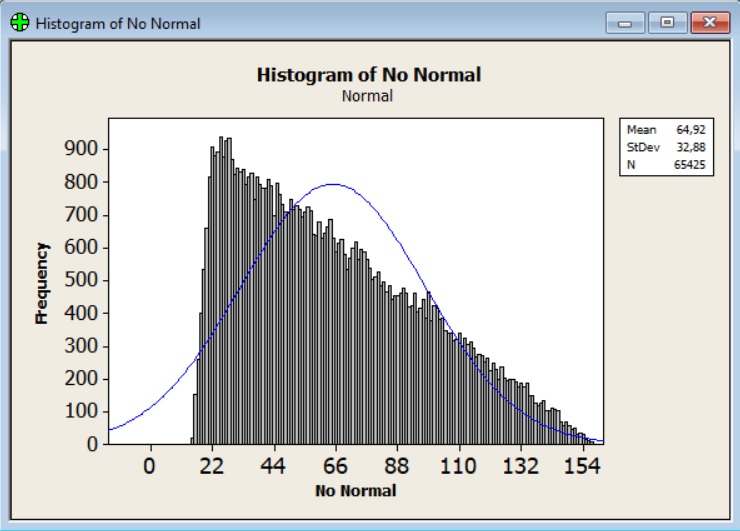
Wyraźnie widać, że liczący 2000 pomiarów zbiór danych czasu obsługi klienta w urzędzie nie ma charakteru rozkładu normalnego. Wykres jest niesymetryczny, wyraźnie widać lewostronną skośność.
Powyższy rozkład danych mimo swojej skośności ma kształt rozkładu normalnego i może być w ograniczonym stopniu poddany dalszej analizie opartej na rozkładzie normalnym. Można spotkać populacje, których rozkłady prawdopodobieństwa zupełnie nie pasują do charakterystyki rozkładu normalnego.