

Klasyfikator SVM wykorzystuje algorytm optymalizacji w oparciu o maksymalizację marginesu hiperplanu. Algorytm SVM jest przeznaczony do prowadzenia możliwie najlepszej klasyfikacji wyników. Wektory oddzielające hiperprzestrzenie mogą mieć charakter liniowy lub (dzięki funkcji SVC) nieliniowy.
W naszym modelu zastosujemy liniowy klasyfikator SVM.
Ćwiczenie przeprowadzimy na próbce badań laboratoryjnych przeprowadzonych na 768 pacjentów. Dane do ćwiczenia z pełnym opisem można znaleźć tutaj: https://www.kaggle.com/kumargh/pimaindiansdiabetescsv
Na początek otworzymy bazę wraz z niezbędnymi bibliotekami.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pprint
from sklearn.pipeline import Pipeline
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.externals import joblib
df = pd.read_csv('c:/1/diabetes.csv', usecols=['Pregnancies', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'Age', 'Outcome'])
df.head(3)
Dokonujemy wyboru funkcji celu y jako kolumny 'Outcome’ oraz usuwamy tą kolumnę ze zbioru zmiennych opisujących X.
X=df.drop(['Outcome'],axis=1) Y=df['Outcome']
Transformacja i klasyfikacja
Tworzymy obiektu pipeline jako połączenie transformatora i klasyfikatora.
Transformator ‘StandardScaler()’ standaryzuje zmienne do populacji opisanej na standaryzowanym rozkładzie normalnym.
Jako estymatora użyliśmy Support Vector Machine (SVM) specjalizującym się w klasyfikacji próbek w kierunku maksymalizacji marginesu pomiędzy grupami danych.
W tym badaniu przyjmiemy klasyfikator liniowy.
ew = [('scaler', StandardScaler()), ('SVM', SVC())]
pipeline = Pipeline(ew)
Istnieją dwa parametry dla jądra SVM, mianowicie C i gamma. Powinniśmy ustawić siatkę parametrów przy użyciu wielokrotności 10. Deklarujemy przestrzeń hiperparametrów. Najlepsza konfiguracja hiperparametrów zostanie wybrana w drodze dostrajania modelu przez GridSearchCV.
parameteres = {'SVM__C':[0.001,0.1,10,100,10e5], 'SVM__gamma':[0.1,0.01]}
Tworzymy zestaw danych do dalszej transformacji i estymacji. Przyjmujemy 20% wartości w tabeli za zbór danych testowych a 80% za zbiór danych treningowych. Parametr ‘random_state’ określa stabilność, nie ma znaczenia liczba jaką tam wpiszemy. Opuszczenie parametru ‘random_state’ będzie powodowało, że model przy każdym uruchomieniu będzie generował inne wartości losowe, co będzie prowadziło do destabilizacji obliczeń.
X_train, X_test, y_train, y_test = train_test_split(X,Y,test_size=0.2, random_state=30, stratify=Y)
Parametr stratify=y powoduje odwzorowanie struktury estymatora do struktury populacji. Dzięki temu parametrowi proporcje określonych wartości w próbce testowej będą taki sam, jak proporcja w próbce treningowej.
Dostrajanie modelu
grid = GridSearchCV(pipeline, param_grid=parameteres, cv=5) grid.fit(X_train, y_train)
Powyższy kod odpowiada za dostrajanie modelu.
Istnieją dwa sposoby szukania najlepszych hiperpartametrów do dostrojenia modelu:
- szukanie przez siatkę (tzw. ‘Grid’)
- szukanie losowe
GridSearchCV – nielosowa metoda dostrajania modelu siatki.
W Pipeline wskazaliśmy metody transformatora: StandardScaler() i estymator: Support Vector Machine.
Następnie w kodzie Hyperparameters – wskazaliśmy parametry: 'SVM__C’oraz 'SVM__gamma’.
Ponieważ używamy GridSearchCV, ta funkcja decyduje o najlepszej wartości w 'SVM__C’ i innych zadanych hiperparametrach w zależności od tego, jak dobrze klasyfikator działa na zbiorze danych.
Zobaczmy jakie parametry są najlepsze według GridSearchCV:
pparam=pprint.PrettyPrinter(indent=2) print(grid.best_params_)
![]()
Czas sprawdzić, na ile nasz model jest dobry, na ile trafnie opisuje rzeczywistość.
Przypomnijmy że celem modelu było wskazanie na podstawie wyników badań czy dany pacjent jest chory na cukrzycę czy nie. Czyli odpowiedź modelu w postaci zmiennej zależnej y powinien wynosić 0 lub 1.
y_pred = grid.predict(X_test) y_pred = np.round(y_pred, decimals=0)
Ocena modelu przez Confusion Matrix
Do oceny naszego modelu tworzącego odpowiedzi binarne, użyjemy Confusion Matrix.
Macierz wskazuje na ile model trafnie typuje odpowiedzi. Zestawia się tu odpowiedzi ze zbioru testowego z odpowiedziami uzyskanymi w drodze predykcji.
from sklearn.metrics import classification_report, confusion_matrix print(confusion_matrix(y_test, y_pred)) print(classification_report(y_test, y_pred))
Macierz ma dwa wymiary ponieważ odpowiedzi mają charakter binarny.
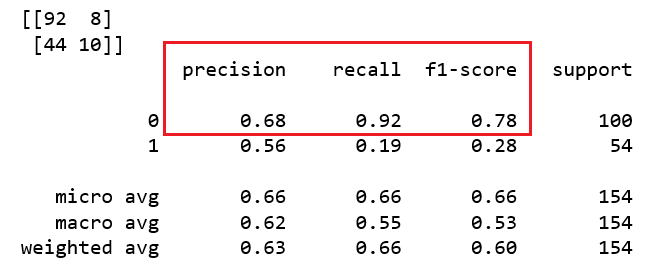
Jak interpretować Confusion Matrix?
Macierz wskazuje ile razy model trafnie wytypował odpowiedź a ile razy się pomylił.
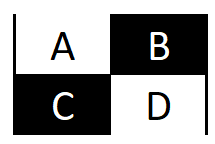
Liczby w polach białych oznaczają ilość trafnych typowań, zaś liczby w czarnych polach oznaczają typowania błędne. Intuicyjnie będziemy lepiej oceniali modele, które mają istotną przewagę w polach białych nad polami czarnymi.
Celność modelu (accuracy (ACC)) jest interpretowana jako dokładność klasyfikacji. Jest liczona jako suma liczb z białych pól do sumy liczb ze wszystkich pól: ACC = A+D / A+B+C+D. Czym wyższa wartość procentowa tym lepiej.
Precyzja modelu (precision or positive predictive value (PPV)) czyli poziom sprawdzalności prognoz modelu. Jest liczona jako PPV = A / A+B.
Odwołanie modelu (sensitivity, recall, hit rate, or true positive rate (TPR))– w ilu przypadkach obecni pacjenci z cukrzycą są identyfikowani przez model jako chorzy. Jest liczona jako TPR = A / A+C.
F-Score
Trudno jest porównać model z niskim Precision i wysokim Recall i odwrotnie.
Aby porównać modele należy użyć F-Score, które mierzy jednocześnie Recall i Precision.
F-Score = (2* Precision* Recall)/( Precision+ Recall) = 2A/(2A+B+C)
Porównanie estymatorów
Teraz zestawimy model oparty o estymator Support Vector Machine z modelem z poprzedniego przykładu opartym o estymator Random Forest.
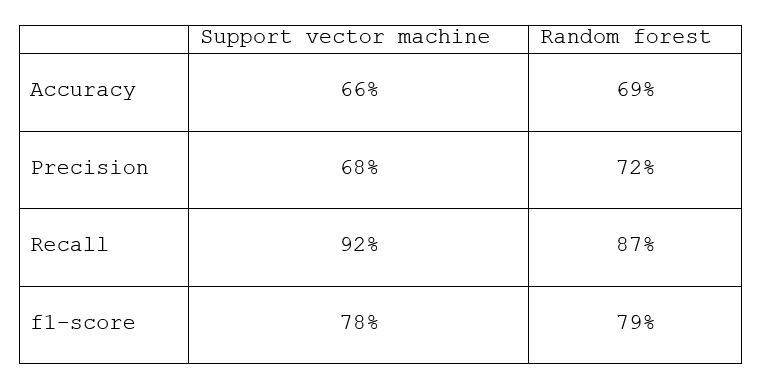
Widzimy, że wyniki estymacji Support Vector Machine versus Random Forest niewiele się różnią.
Praktyczne użycie modelu Machine learning
Model możemy zapisać używając kodu:
joblib.dump(grid, 'c:/1/rf_SVM.pkl')
Możemy odczytać zapisany wcześniej model:
clf2 = joblib.load('c:/1/rf_SVM.pkl')
Wyniki predykcji możemy podstawić do wynikowych danych empirycznych.
lf2.predict(X_test)
X = df.drop('Outcome', axis=1)
WYNIK = clf2.predict(X)
df['MODEL'] = pd.Series(WYNIK)
df['Result'] = df['MODEL'] - df['Outcome']
df[['Outcome','MODEL', 'Result']].sample(10)
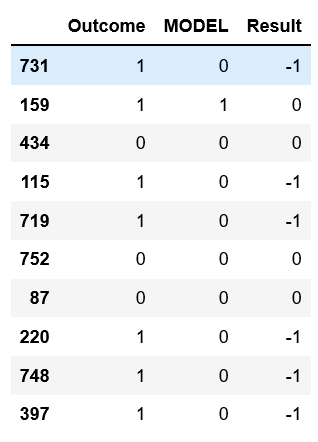
cdf['Result'].value_counts()

df['Result'].value_counts(normalize=True)
