

Using loops in place of gaps I insert values out of range¶
## ile jest zmiennych
a,b = df.shape #<- ile mamy kolumn
b
print('NUMBER OF EMPTY RECORDS vs. FULL RECORDS')
print('----------------------------------------')
for i in range(1,b):
i = df.columns[i]
r = df[i].isnull().sum()
h = df[i].count()
if r > 0:
print(i,"--------",r,"--------",h)
del df['Cabin']
df = df.dropna(how='any')
df = df.dropna(how='any')
df.isnull().sum()
df.shape
Encodes discrete (categorical) variables¶
import numpy as np
a,b = df.shape #<- ile mamy kolumn
b
print('DISCRETE FUNCTIONS CODED')
print('------------------------')
for i in range(1,b):
i = df.columns[i]
f = df[i].dtypes
if f == np.object:
print(i,"---",f)
if f == np.object:
df[i] = pd.Categorical(df[i]).codes
continue
I run the LinearRegression () model
y = df['Survived']
X = df.drop('Survived', axis=1)
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor()
model.fit(X, y)
#import xgboost
import shap
shap.initjs()
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)

Interpretation of SHAP diagnostic charts¶
Interpretacja wykresów diagnostycznych SHAP
Graph (1) of overall function suitability assessment¶
Wykres (1) ogólnej oceny przydatności funkcji
shap.summary_plot (shap_values, X)
Chart interpretation:
• The x axis represents the SHAP value (which for this model is in logarithmic chances of winning). By analyzing the validity for all functions, we can see which features greatly affect the model’s predictive ability (e.g. ‘Sex’ and ‘Pclass’), and which only slightly influence predictability (e.g. Parch, Embarked). Note that when the points do not form a horizontal line, they stack up vertically to show density.
• Each dot is colored with a high red to blue low effect value. Each point is a Titanic man. one sex affected the model’s assurance of prognosis, while the other significantly reduced the forecasting abilities of the model.
• So it would be enough to somehow pull a woman and class 1 and the rest of the passengers. The other functions are only mixed up. This function counts where the blue and red enclaves are clean (‘Sex’ and ‘Pclass’).
- The most important function in the model is ‘Sex’, slightly less important is ‘Pclass’, i.e. in which class the passenger traveled.
- The importance of the feature on the ability to forecast: blue is low ability to forecast – red is the high ability of the model to forecast.
- In the case of ‘Sex’ and ‘Pclass’ there are great differences between the sexes and between the classes in which travelers traveled.
- ‘Name’, ‘PassangerId’, ‘Ticket’ you can see that there is no separation here and there is full randomness, the data is centered around 0 on the SHAP value axis.
Interpretacja wykresu:
– Oś x przedstawia wartość SHAP (która dla tego modelu jest w jednostkach logarytmicznych szans na wygraną). Robiąc analizę ważności dla wszystkich funkcji, widzimy, które cechy bardzo wpływają na zdolności przewidywania modelu (np. ‘Sex’ i ‘Pclass’ ), a które tylko nieznacznie wpływają na przewidywanie (np. Parch, Embarked). Zauważ, że gdy punkty nie tworzą linii poziomej, układają się w pionowe stosy, aby pokazać gęstość.
– Każda kropka jest zabarwiona wartością wpływu tej cechy od wysokiej czerwonej do niebieskiej niskiej. Każdy punkt to człowiek z Titanica. jedna płeć wpływała na upewnienie się modelu co do prognozy a druga płeć istotnie obniżała zdolności prognostyczne modelu.
– Czyli wystarczyłoby jakoś wyciągnąć kobieta i klasa 1 i reszta pasażerów. Pozostałe funkcje tylko mieszają. Ta funkcja się liczy gdzie są czyste enklawy niebieskie i czerwone (‘Sex’ i ‘Pclass’).
1. Najważniejszą funkcją w modelu jest ‘Sex’ nieco mniej ważną jest ‘Pclass’ czyli, w której klasie podróżował pasażer.
2. Ważność cechy na zdolność do prognozowania: niebieski to niska zdolność do prognozowania – czerwony to wysoka zdolność modelu do prognozowania
3. W przypadku ‘Sex’ i ‘Pclass’ istnieją wielkie różnice między płciami i miedzy klasami, w których podróżowali podróżni
4. ‘Name’, ‘PassangerId’, ‘Ticket’ widać, że tu nie ma rozdzielenia i jest pełna losowość, dane są skupione wokół 0 na osi SHAP value
shap.dependence_plot(“Sex”, shap_values, X)

Chart interpretation:
- This chart shows that women (marked as 0) differ in their impact on model estimation accuracy.
Women are aptly typed by the model. Men are incorrectly selected.
SHAP has yet automatically added the nearest relevant Pclass function. -
The model most accurately estimates women from class 2, and the least from the set of women, those women who traveled in third class. In general, the values of women on the y-axis above zero mean that the model well predicted the fate of women and weaker the fate of men.
-
Men from class 3 (red) were tipped quite aptly (certain that they would die). The model had a problem with men in classes 2 and 3 (had difficulty predicting or dying).
Interpretacja wykresu:
– Na tym wykresie widać, że kobiety (oznaczone jako 0) różnią się wpływem na trafność szacowania modelu.
Kobiety są trafnie typowane przez model. Mężczyźni są typowani nietrafnie.
SHAP jeszcze dodał automatycznie najbliższą istotną funkcję Pclass.
– Najtrafniej model szacuje kobiety z klasy 2, a najmniej ze zbioru kobiet, te kobiety, które podróżowały klasą trzecią.
Ogólnie wartości kobiet na osi y powyżej zera oznaczają, że model dobrze przewidywał los kobiet a słabiej los mężczyzn.
– Mężczyźnie z klasy 3 (kolor czerwony) byli typowani dość trafnie (pewne, że zginą). Model miał problem z mężczyznami z klasy 2 i 3 (miał trudność z przewidzeniem czy zginą).
shap.dependence_plot(“Pclass”, shap_values, X)

The figure above shows
- class 1: half and half women = 0 (blue) and men = 1 (red). In the first class, the model coped well with forecasts, much better in class 1 forecasting what would happen to women than men.
- In class 3 the model had a very big problem with predicting what would happen to women, each blue point is one woman. As for the fate of men in class 3, the model predicted quite well – close to baseline.
- The conclusion is – if you throw women from class 3 from the data, the model would improve your ratings.
Na powyższym rysunku widać
– klasę 1: pół na pół kobiety = 0 (niebieskie) i mężczyzn = 1 (czerwone). W klasie pierwszej model dobrze radził sobie z prognozami, znacznie lepiej w klasie 1 prognozował co stanie się z kobietami niż mężczyznami.
– W klasie 3 model miał bardzo duży problem z przewidzeniem co stanie się z kobietami, każdy niebieski punkt to jedna kobieta. Co do losu mężczyzn z klasy 3 model prognozował dość dobrze – blisko wartości bazowej.
– Nasuwa się wniosek – gdyby wyrzucić z danych kobiety z klasy 3 model poprawiłby swoje notowania.
shap.dependence_plot(“Age”, shap_values, X)

Interpretation:
-
The model coped well with predicting the fate of children, people from zero to 10 years old. Values above zero can be seen on the y axis.
-
Above this age, the model could not very well indicate the fate of people. Forecasts are getting worse when people are older.
- spend on the cloud that the blue dots are above, which means that the model better predicted the fate of people from class 1 (blue dots) than from class three (red dots)
Interpretacja:
– Model doskonale radził sobie z przewidywaniem losu dzieci, osób w wieku od zera do 10 lat. Widać na osi y wartości powyżej zera.
– Powyżej tego wieku model nie umiał wskazywać bardzo dobrze na los osób. Prognozy pogarszają sie czym starsze są osoby.
– wydać na chmurze, że niebieskie kropkli są powyżej, co oznacza, że model lepiej przewidywał los ludzi z klasy 1 (niebieskie kropki) niż z klasy trzeciej (czerwone kropki)
shap.summary_plot(shap_values, X, plot_type=”bar”)shap_interaction_values = shap.TreeExplainer(model).shap_interaction_values(X.iloc[:500,:])
shap.summary_plot(shap_interaction_values, X.iloc[:500,:])

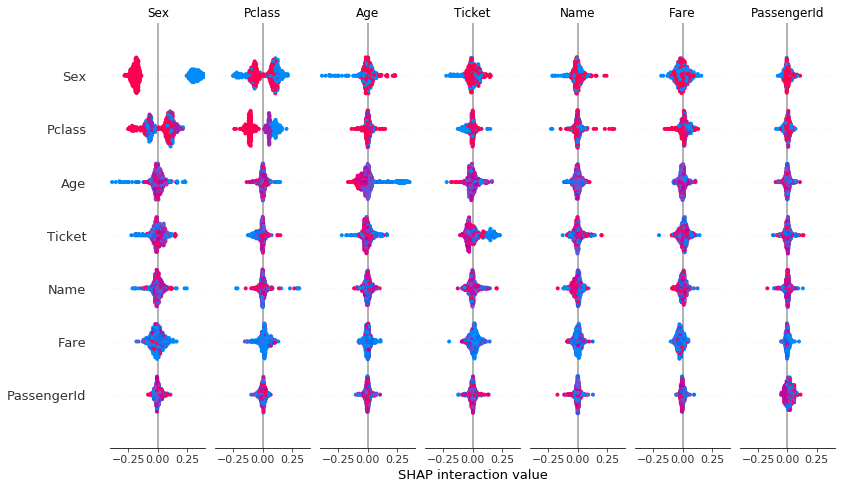
Interpretation:
-
statement: ‘Sex’ vs ‘Pclass’ shows that there are strong differences affecting the quality of forecasting.
-
‘Age’ vs ‘Sex’ has an illegible result
-
the rest of the features are piled around zero and therefore have a low impact on improving or deteriorating forecasting quality.
Interpretacja:
– zestawienie: ‘Sex’ vs ‘Pclass’ pokazuje że istnieją mocne różnice wpływające na jakość prognozowania.
– ‘Age’ vs ‘Sex’ ma nieczytelny wynik
reszta cech jest zbita w stosy wokół zera i przez to mają niski wpływ na poprawę lub pogorszenie jakość prognozowania.